

Experte
13
Jun
2018
2018
von Ulrich Plogas
Forum: Big Data Einsatzszenarien
Aber es geht auch anders. „Big Data“ steht ja auch – zumindest in den Grundkomponenten – für Open Source und so ist der Gedanke naheliegend, die Karten einmal neu zu mischen. Hier wird in lockerer Folge über die Erfahrungen berichtet, mittels „Apache Spark“ auf die NoSQL-Datenbank „MongoDB“ zuzugreifen.
Beide Komponenten können gut skalieren und sind weit verbreitet. „Spark“ hat sich schnell zu einer Art Schweizer Taschenmesser für die verteilte Verarbeitung entwickelt. „MongoDB“ ist eine Dokument-basierte Datenbank. Genaue Installationszahlen sind naturgemäß nicht nachzuvollziehen, aber allgemein wird dieser Datenbank der höchste Verbreitungsgrad im NoSQL-Sektor eingeräumt.
Die erste Folge beschreibt kurz den architekturellen Ansatz und beschäftigt sich mit der Installation der Komponenten.
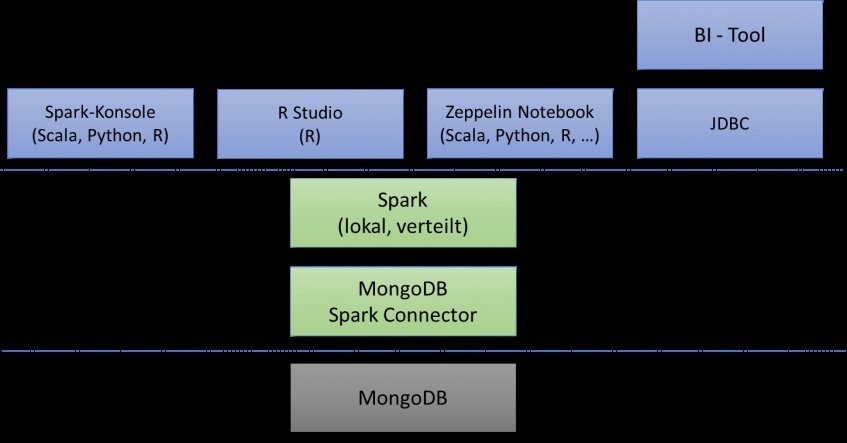
Der grundsätzliche architekturelle Ansatz besteht aus dem Daten-Backend, welches durch die MongoDB repräsentiert wird sowie einer Verarbeitungsschicht, die durch Spark und der Zugriffskomponente für die MongoDB besteht. Beide Schichten können sowohl auf einem einzelnen Knoten als auch verteilt über mehrere oder gar viele Knoten implementiert werden. Darüber hinaus bestehen die unterschiedlichsten Möglichkeiten der Interaktion durch den Anwender (siehe Bild).
Um die Konzentration auf das Wesentliche zu ermöglichen, wird im ersten Schritt lediglich eine lokale Installation in einer Linux-Umgebung mit CentOS durchgeführt. Dazu wird in der Azure-Cloud eine Instanz vom Typ E2 (zwei CPU-Kerne, 16 GB RAM) mit der MongoDB sowie eine Instanz vom Typ D12 (vier CPU-Kerne, 28 GB RAM) mit Apache Spark bestückt. Auf letzterer wird zusätzlich noch die Notebook-Anwendung Apache Zeppelin sowie der Connector für die Verbindung zur Datenbank installiert.
Alle diese Komponenten gibt es als installationsfähige Pakete, so dass die aufwändige Kompilierung von Quellprogrammen nicht erforderlich ist. Die einzige Herausforderung besteht in der Auswahl der „richtigen“ Komponenten. Zum Zeitpunkt der ersten Tests war die aktuelle Version des MongoDB Spark Connectors die Version 2.2.1, die allerdings nicht mit der aktuellen Spark Version 2.3 harmoniert und deshalb die Vorgängerversion 2.2 erfordert. Die aktuelle Version 0.7.3 des Zeppelin Notebooks kann jedoch mit Spark 2.2 verwendet werden. Für alle Komponenten kommt das JDK 8 zum Einsatz.
Nach dem Kopieren und Entpacken des Spark-Paketes wird das Java-Archiv des Connectors in das Verzeichnis „jar“ von Spark kopiert. Anschließend werden die Dateien für das Notebook Zeppelin in ein beliebiges Verzeichnis entpackt.
Nach der Einrichtung der Umgebungsvariablen ist die Testumgebung prinzipiell startklar. Ein letzter Schritt ist erforderlich, um den Connector und die MongoDB in der Umgebung von Spark bekannt zu machen. Dafür stehen verschiedene Möglichkeiten zur Verfügung:
- Durch Einträge in der Konfigurationsdatei $SPARK_HOME/conf/spark-default.conf;
- Durch Konfiguration bei der Generierung des SparkContext;
- Durch Übergabe der Parameter beim Aufruf der Shell (spark-shell, pyspark, sparkR).
Es besteht grundsätzlich die Möglichkeit, eine Standardeinstellung in der Konfigurationsdatei festzulegen und diese bei Bedarf beim Aufruf mit aktuellen Parametern zu überschreiben.
Auch für das Notebook Zeppelin muss eine Anpassung vorgenommen werden, darauf wird jedoch in einem späteren Eintrag eingegangen. Die nächste Folge beschäftigt sich zunächst mit dem Wechselspiel zwischen Spark und MongoDB.
Hot Wheels - Folge 3: Datenanalyse und Machine Learning mit MongoDB und Spark
https://www.qualiero.com/community/big-data-hadoop/big-data-einsatzszenarien/hot-wheels-folge-3-datenanalyse-und-machine-learning-mit-mongodb-und-spark.html
Hot Wheels - Folge 2: Datenanalyse und Machine Learning mit MongoDB und Spark
https://www.qualiero.com/community/big-data-hadoop/big-data-einsatzszenarien/hot-wheels-folge-2-datenanalyse-und-machine-learning-mit-mongodb-und-spark.html

