

Expert
24
May
2018
2018
by Marc-David Militz
Forum: MongoDB Theorie
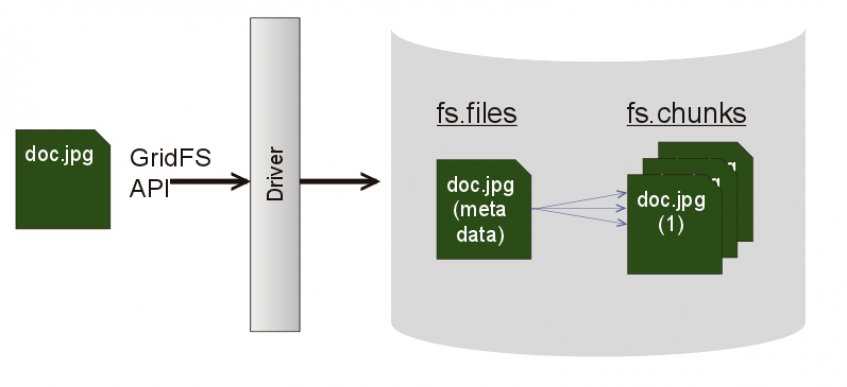
MongoDB hat dafür ein eigenes Konstrukt mit dem Namen GridFS geschaffen. Die Dateien werden dabei auf zwei Collections aufgeteilt. Die Metadaten-Collection enthält alle Informationen zu den Dateien. In der Chunks-Collection wird die, in Chunks zerlegte, Datei selbst abgelegt.
Der Einsatz von GridFS ist vor allen dann sinnvoll wenn
mongofiles -d gridfs put Nyan_Cat-15_Minutes.mp3
Ist die Datei dann in GridFS geladen kann man in der Mongo Konsole die einzelnen Chunks sehen und kann auch darauf zugreifen.
Beispiel für den Zugriff
db.fs.files.find().pretty()
db.fs.chunks.find({files_id:ObjectId(object_id)})
db.fs.chunks.find({files_id:ObjectId(object_id)}).count()

